New Oral History Transcription Workflow
Attention: This post supersedes posts/077-oral-history-transcription-workflow.md.
Digital.Grinnell features a fair number of transcribed digital oral histories. Most are interviews conducted with Grinnelleans as they return to campus annually for alumni Reunion or Grinnell’s Multicultural Reunion.
What follows is largely sharable “public” content lifted from a “private” GitHub repository at https://github.com/McFateM/OHScribe, the README.md and WORKFLOW.md files in particular.
OHScribe!
https://ohscribe.us.reclaim.cloud/
Note: This link is the new production home for OHScribe! as of March 2022. It is now hosted on Reclaim Cloud. The old address, https://ohscribe.grinnell.edu, is no longer in service.
OHScribe! code now resides in a private repository so a copy of its shared documents are also provided as public gists. They are:
This is a Python 3 and Flask web application designed to transform oral history transcripts, presumably created using InqScribe, into XML suitable for ingest into the Islandora Oral Histories Solution Pack to populate a TRANSCRIPT datastream and its derivatives. Islandora Oral Histories and the aforementioned solution pack are commonly referred to as IOH throughout this document.
OHScribe! is intended to be used as part of a broader IOH transcription workflow developed at Grinnell College. The workflow documented in the section titled The Digital.Grinnell Oral History Workflow may be of significant interest to individuals tasked with transcribing IOH audio recordings. The aforementioned workflow document now includes a link to an 11.5 minute long training video.
Formatted IOH Example
The aforementioned workflow, application, and accompanying CSS (provided below) are intended to deliver oral histories that look something like this:

Note that the names of speakers appear in different colors in the video window captions, and speaker names appear in bold in the indexed transcript below the video. Each speaker and corresponding text appears on a new line, and captions are superimposed over a thumbnail image of the speaker(s).
InqScribe IOH Transcription Workflow
A detailed description of the workflow intended for use with OHScribe! is provided in our WORKFLOW.md document.
Workflow Output
The workflow documented in the aforementioned WORKFLOW.md should produce an XML formatted transcript which resembles the structure of the following example.
Note that a sample of transcript XML, suitable for testing, now exists in the OHScribe! codebase at https://github.com/DigitalGrinnell/OHScribe/blob/reclaim/test/sample-from-InqScribe.xml.
<transcript>
<prologue/>
<scene id="1" in="00:00:00.21" out="00:00:12.07"><speaker> Heather Riggs </speaker>
Heather | Okay, so.. Yeah, just before we start, if you could each go around and say your name, your class year, and where you live now, just for the microphone.</scene>
<scene id="2" in="00:00:12.08" out="00:00:18.02"><speaker> Margo Gray </speaker>
Margo | Cool. I’m Margo Gray of the class of 2005, and, what else am I saying?</scene>
<scene id="3" in="00:00:18.03" out="00:00:19.07">Heather | Your home.
<speaker> Maggie Montanaro </speaker>
Maggie | Where you live.</scene>
<scene id="4" in="00:00:19.08" out="00:00:21.14">Margo | I live in Chicago, Illinois.</scene>
<scene id="5" in="00:00:21.15" out="00:00:26.07"><speaker> Jenny Noyce </speaker>
Jenny | My name is Jenny Noyce, the class of 2005 and I live in Oakland, California.</scene>
<scene id="6" in="00:00:26.08" out="00:00:32.11">Maggie | I’m Maggie Montanaro, also class of 2005, and I live in Avignon, France.</scene>
<scene id="7" in="00:00:32.12" out="00:00:39.17">Heather | Wow. So, what are your strongest memories of Grinnell?</scene>
<scene id="8" in="00:00:39.18" out="00:00:45.05">Maggie | Harris Parties.</scene>
<scene id="9" in="00:00:45.06" out="00:00:53.00">Jenny | Mud sliding in the rain.
Maggie | Yeah, mud wrestling. Mud sliding on Mac Field. Lots and lots of work.</scene>
<scene id="10" in="00:00:53.01" out="00:01:30.27">Margo | I guess I remember people, like, I still am in touch with a lot of people from Grinnell and yeah. So I don’t, I mean I don’t have like
these really specific memories of like meeting people, but just mostly, like this whole sort of like pool of memories of times when I was hanging out with people or working with people or, yeah. Building the sort of, you don’t think of it when you’re there, it’s not like, "Ah, I’m building connections to last me!" You’re just like, "I’m hanging out with my friends." But those sort of things tend to last.
Maggie | Lots of good hanging out.
Margo | Yes.</scene>
<scene id="11" in="00:01:30.28" out="00:02:01.00">Heather | What kind of Harris parties did you have? Like themed...
Maggie | All the, I assume they still have them, the hall ones like the Haines Underwear Ball, the Mary B. James, Disco... what else? Lots of just themed…
Jenny | They started a fetish party.
Maggie | Really? They still have fetish?
Jenny | I never went to that one. Maybe I was too close-minded.
Maggie | Yeah.</scene>
<scene id="12" in="00:02:01.01" out="00:02:18.14">Heather | What are your first memories of Grinnell?
Key parts of this exported transcript example are described in the sections below.
<scene> Tags
<scene> tags enclose data indicating who is speaking along with transcribed text from the recording. <scene> tags also include attributes indicating the position or scene’s id, in and out times provided in hours-minutes-seconds, or hh:mm:ss.s notation, and one or more optional <speaker> tags.
<scene id="1" in="00:00:00.21" out="00:00:12.07">
<speaker> Heather Riggs </speaker>
Heather | Okay, so.. Yeah, just before we start, if you could each go around and say your name, your class year, and where you live now, just for the microphone.
</scene>
The example <scene> tag shown above carries an id of ‘1’, it’s the first scene in the transcript, with in and out times provided in hours-minutes-seconds, or hh:mm:ss.s notation. The in and out attributes indicate when the transcribed text is heard in the audio stream. This scene also encloses a <speaker> tag which, in this case, identifies the speaker “Heather”, as an individual with a full name of “Heather Riggs”.
The text of this scene, a single sentence, opens with a required speaker ID, the name of the speaker, Heather, followed by a pipe (|) delimiter.
This demonstrates an important rule… Each line of transcribed text MUST begin with a speaker ID, a given/first name, or single word identifying the speaker, followed by a pipe delimiter.
<scene id="11" in="00:01:30.28" out="00:02:01.00">
Heather | What kind of Harris parties did you have? Like themed...
Maggie | All the, I assume they still have them, the hall ones like the Haines Underwear Ball, the Mary B. James, Disco... what else? Lots of just themed…
Jenny | They started a fetish party.
Maggie | Really? They still have fetish?
Jenny | I never went to that one. Maybe I was too close-minded.
Maggie | Yeah.
</scene>
The example <scene> tag shown above, with an id of ‘11’, includes in and out time attributes, and seven lines of transcribed text. Each line begins with a speaker ID, in this case the given/first name of the speaker followed by a pipe (|) delimiter. Note that this scene has NO <speaker> tags because the speakers: Heather, Maggie, and Jenny; all have corresponding <speaker> tags inside previous scenes.
<speaker> Tags
<speaker> tags are used to identify each speaker in a transcript by providing their full name, and associating the given/first name portion of their full name with subsequent speaker ID prefixes.
At least one <speaker> tag must appear for each speaker ID used in the transcript, and a speaker’s tag must appear BEFORE any/all corresponding speaker IDs.
A <speaker> must occur only within an enclosing <scene> tag.
Speaker ID
As previously mentioned, a speaker ID identifies a speaker by their given/first name or some single-word identifying term, like “Interviewer"or “Interviewee”. Each speaker ID consists of a given/first name, or other single-word identifier, followed by a pipe (|) delimiter.
Spaces around pipe delimiters are recommended, but not required.
XML for Ingest into IOH
The Islandora Oral Histories (IOH) solution pack expects a TRANSCRIPT datastream of <cues> formatted like the following for successful ingest.
<cues>
<cue>
<speaker>Heather Riggs</speaker>
<start>0.21</start>
<end>12.07</end>
<transcript><span class='oh_speaker_1'>Heather: <span class='oh_speaker_text'> Okay, so.. Yeah, just before we start, if you could each go around and say your name, your class year, and where you live now, just for the microphone.</span></span></transcript>
</cue>
<cue>
<speaker>Margo Gray</speaker>
<start>12.08</start>
<end>18.02</end>
<transcript><span class='oh_speaker_2'>Margo: <span class='oh_speaker_text'> Cool. I’m Margo Gray of the class of 2005, and, what else am I saying?</span></span></transcript>
</cue>
<cue>
<speaker>Heather Riggs & Maggie Montanaro</speaker>
<start>18.03</start>
<end>19.07</end>
<transcript><span class='oh_speaker_1'>Heather: <span class='oh_speaker_text'> Your home.</span></span><span class='oh_speaker_3'>Maggie: <span class='oh_speaker_text'> Where you live.</span></span></transcript>
</cue>
<cue>
<speaker>Margo Gray</speaker>
<start>19.08</start>
<end>21.14</end>
<transcript><span class='oh_speaker_2'>Margo: <span class='oh_speaker_text'> I live in Chicago, Illinois.</span></span></transcript>
</cue>
<cue>
<speaker>Jenny Noyce</speaker>
<start>21.15</start>
<end>26.07</end>
<transcript><span class='oh_speaker_4'>Jenny: <span class='oh_speaker_text'> My name is Jenny Noyce, the class of 2005 and I live in Oakland, California.</span></span></transcript>
</cue>
<cue>
<speaker>Maggie Montanaro</speaker>
<start>26.08</start>
<end>32.11</end>
<transcript><span class='oh_speaker_3'>Maggie: <span class='oh_speaker_text'> I’m Maggie Montanaro, also class of 2005, and I live in Avignon, France.</span></span></transcript>
</cue>
In this format each <cue> tag within the enclosing <cues> tag represents one <scene> from the previously documented workflow output. Like a <scene>, each <cue> identifies a speaker, a start and end time, and one or more lines of transcribed text.
OHScribe! can be used to transform output from the documented workflow into this format for ingest.
Running OHScribe!
OHScribe! is accessible at https://ohscribe.us.reclaim.cloud and should run in any web browser. It permits a user to upload an XML file (presumably this is output from the aforementioned workflow), and if successful, it provides an output file in IOH-compatible XML format as a download.
Since upload and download of content is provided the site will present the user with a required login screen like this:
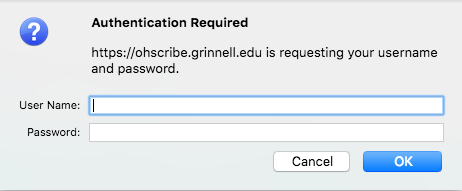
Interested users of OHScribe! should [request credentials via email to digital@grinnell.edu](mailto:digital@grinnell.edu?subject=OHScribe Credentials).
Uploading XML
Once authorized, OHScribe! presents the user with a file upload form like so:
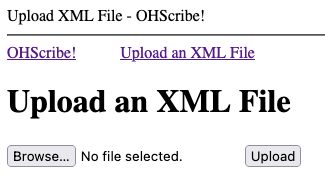
Selecting the Browse... button will open a file-selection window on the local host. The user should select a single .XML transcript file for upload and click the Upload key to send it to the OHScribe! server.
A successful file upload produces Main/Control screen like this:
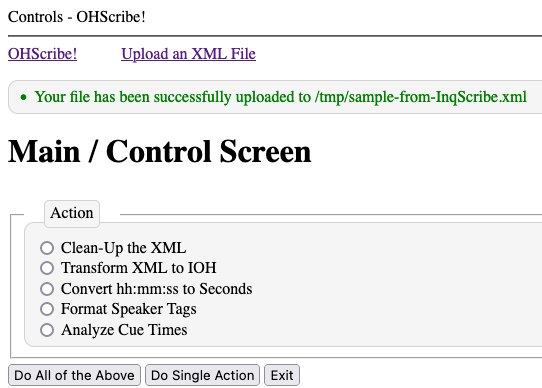
Note the message/status portion of the window just above the Main / Control Screen title. The message here in green print indicates a successful upload.
Typical/Recommended Use
Once an XML file has been successfully uploaded for processing, the user is presented with a six individual or single actions, or a seventh option to Do All of the Above. Users should ALWAYS choose Do All of the Above unless there are special circumstances and they have been instructed otherwise.
Typical use of OHScribe! follows these steps.
- In the Upload an XML File screen click the
Browsebutton and navigate to a transcript XML file prepared in and exported from InqScribe.
This action opens the selected XML file for processing with the path to the file reflected in the box at the top of the GUI.
- In the Main / Control Screen window click the Do All of the Above button.
This inokes the six actions documented below. If successful it will transform the XML exported from InqScribe into the XML form required for IOH ingest, giving the user an option to download the transformed file.
- Click the Download button.
This action converts \<start> and \<end> values from hours:minutes:seconds notation to the decimal seconds notation required for IOH. The changes are saved directly in the selected **IOH-** file. This file should be suitable for ingest into IOH.
Single Actions
OHScribe! divides the transformation of a transcript into six ordered, individual steps represented by the following single Action choices:
Clean-Up the XML - This action checks that the uploaded file has a .xml extension and subsequently parses the XML to verify its validity.
Transform XML to IOH - This action transforms the valid XML creating a
<cues>and enclosed<cue>tags from<scene>tags.Convert hh:mm:ss to Seconds - This action converts all of the in and out time codes from hours-minutes-seconds (hh:mm:ss.s) notation to necessary
<start>and<end>tags expressed as the number of seconds measured from the beginning of the transcribed audio or video stream.Format Speaker Tags - This action transforms all of the speaker tags and speaker IDs from the original transcription into IOH-formatted speaker tags.
Analyze Cue Times - This final action checks each of the
<cue>tag contents against a fixed target of 10 lines. Cues with more than 10 lines of captioning may overwhelm or even overflow the underlying image or video content.
Note that when a single action is performed the user must take steps to download intermediate results and upload those back to OHScribe! in order to perform the next step. Since this can become rather tedious, the option to Do All of the Above is recommended.
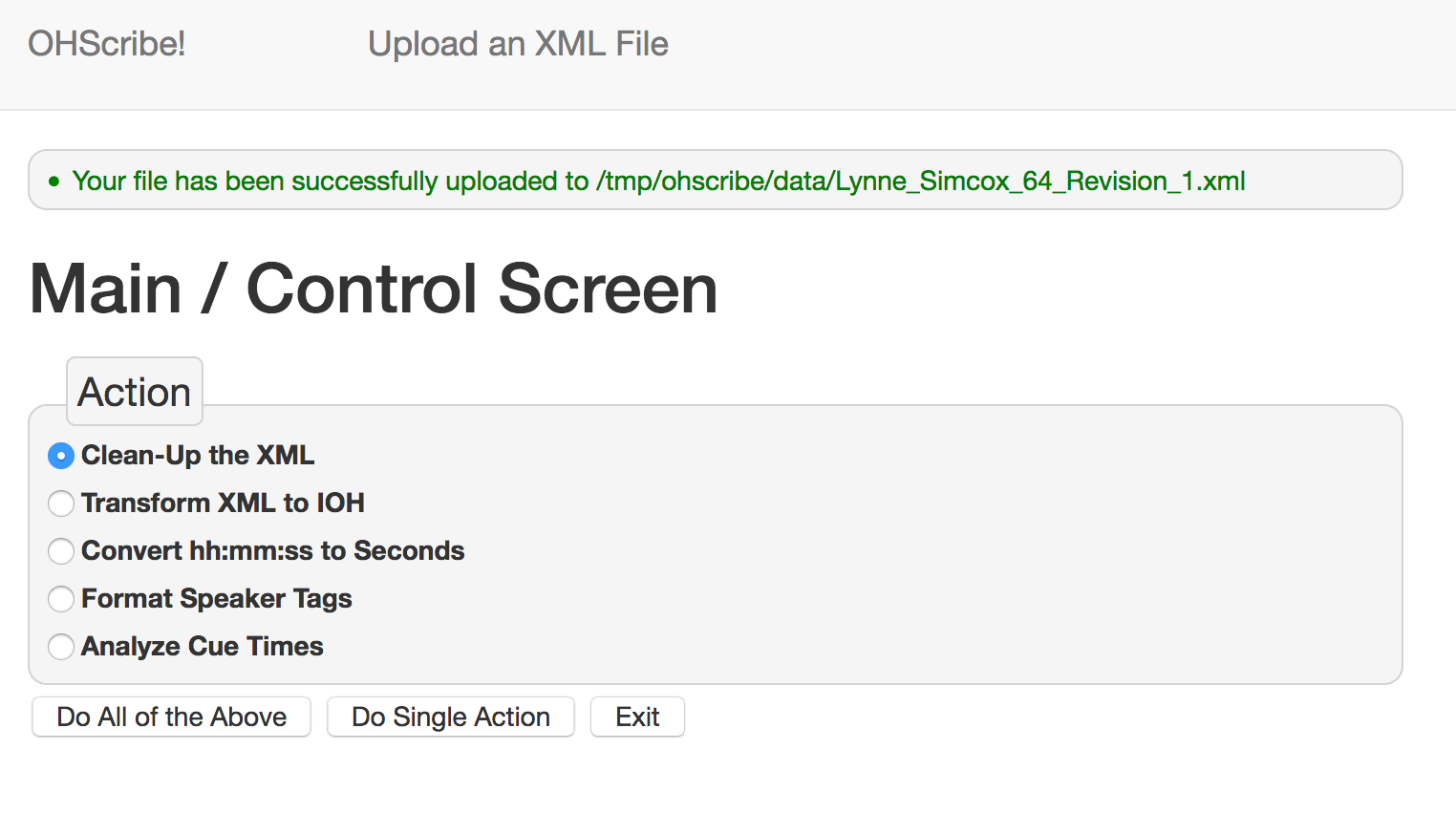
A single action can be performed by clicking the radio button corresponding to the desired action, and clicking the Do Single Action button near the bottom of the Main / Control Screen as shown below.
Action Results
Results of a Do All of the Above action typically include status output in a box at the top of the window, a Message box explaining the outcome, and a Download your Output! button with instructions. The window typically looks something like this:
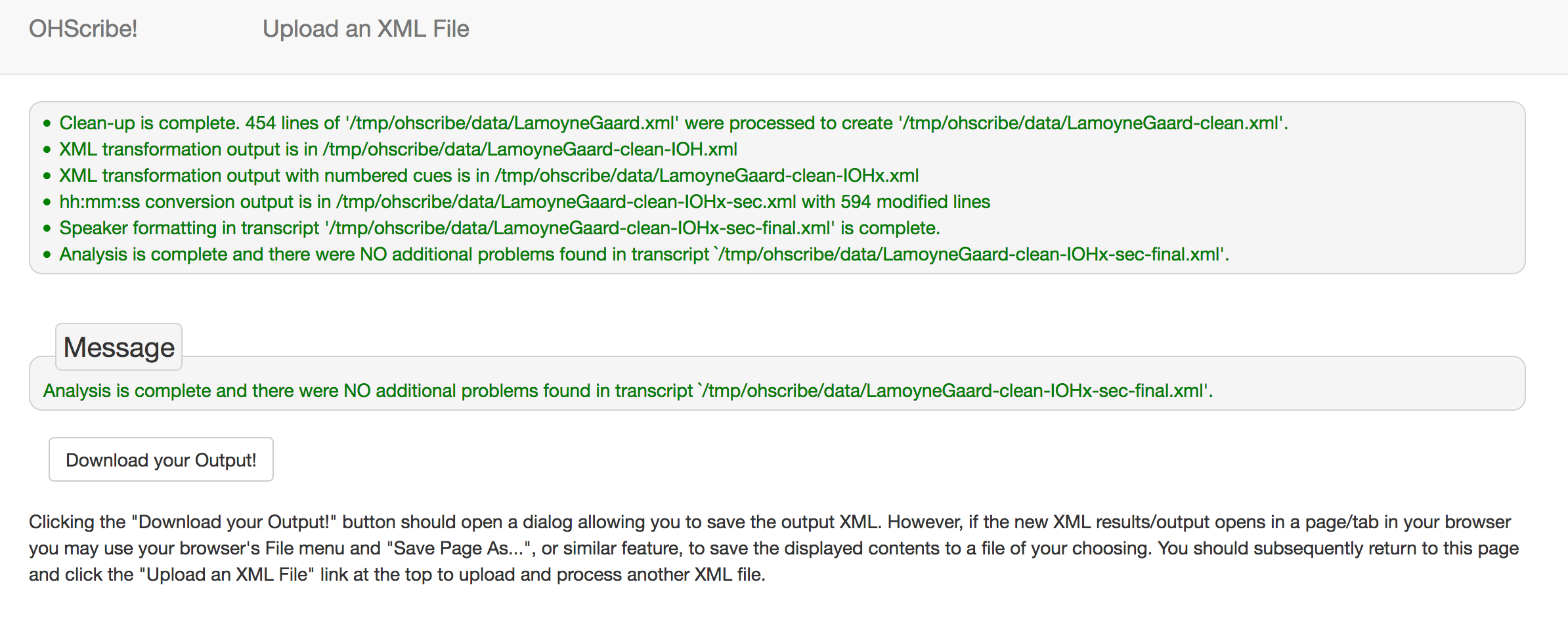
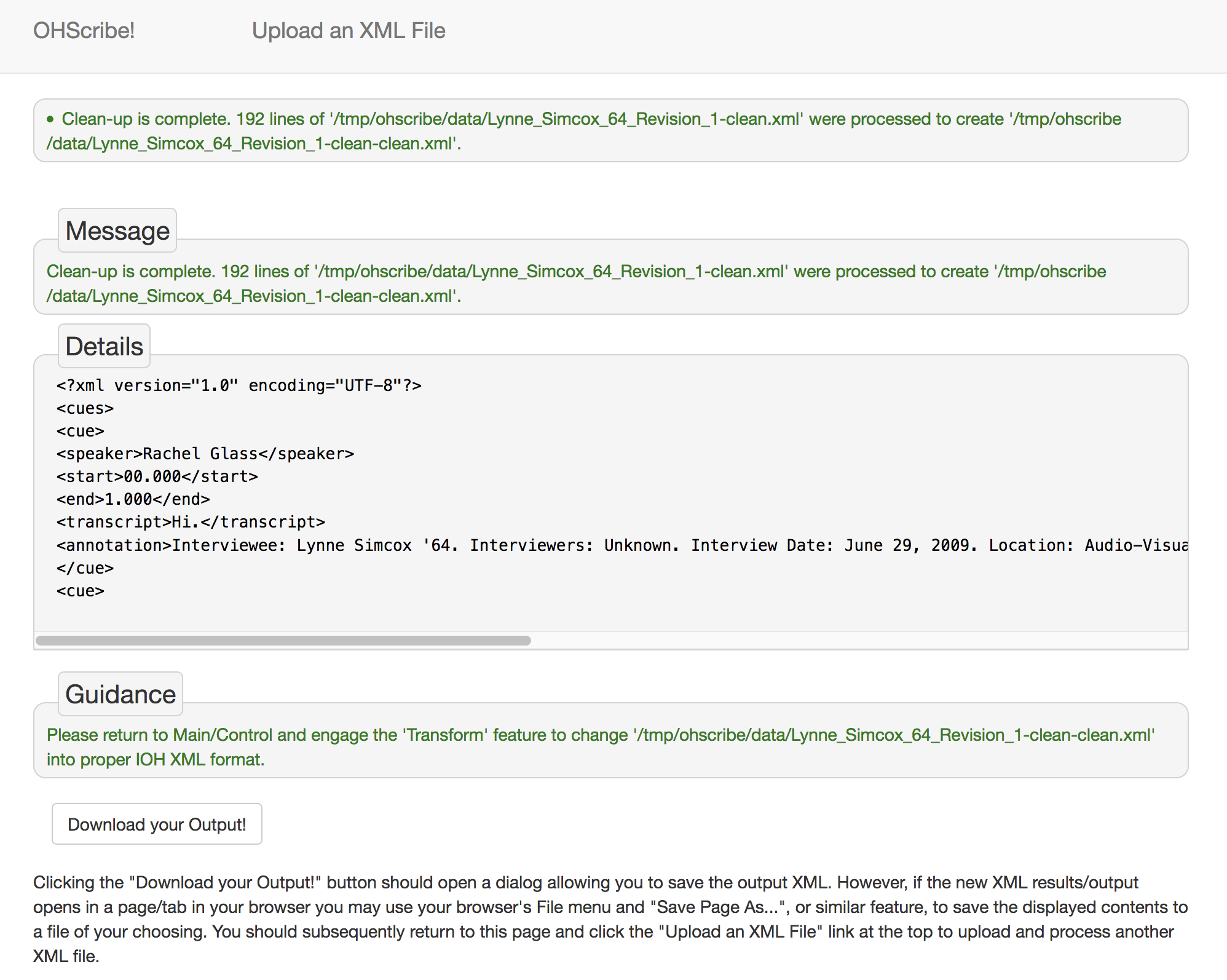
Single actions produce slightly different results which may also include Details of the output, and Guidance for follow-up actions as shown below.
Errors
Processing errors are generally presented with red text appearing in the status box at the top of the window, like so:
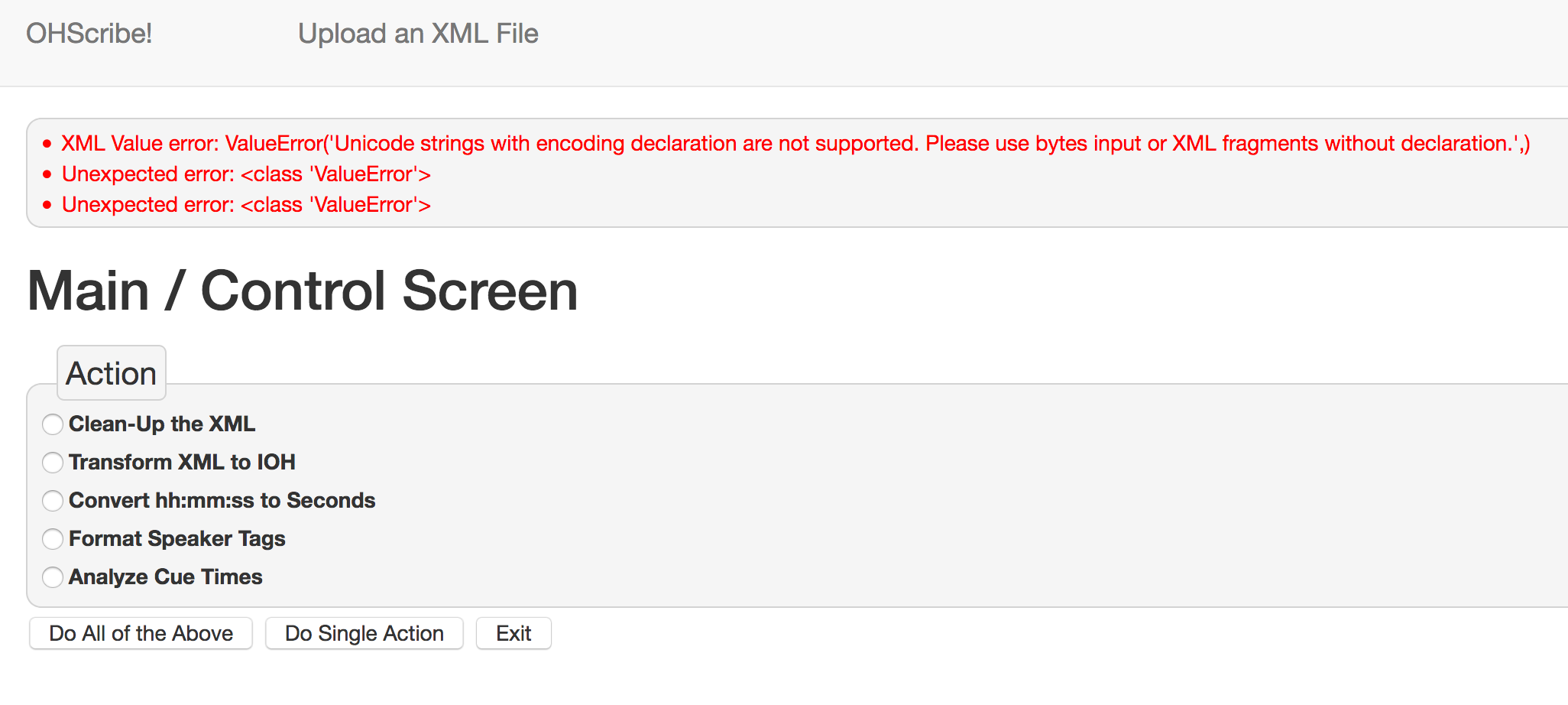
Unexpected or unresolvable errors encountered in OHScribe! should be [reported to the author via email to digital@grinnell.edu](mailto:digital@grinnell.edu?subject=OHScribe Error) and/or added to the Issue queue at https://github.com/DigitalGrinnell/OHScribe/issues.
CSS Required for Speaker Formatting
To take advantage of the script’s “speaker formatting” capabilities you must add the following CSS, or something very similar, to the theme of the site where Islandora Oral Histories are displayed. This CSS produces coloring and formatting like that shown in the example above.
/* Color, display and font additions for Oral Histories */
div.tier.active span {
font-weight: bold;
}
div.tier.active span,
div.tier.active span span.oh_speaker_text {
color: black !important;
}
div.tier.active span span.oh_speaker_text {
font-weight: normal !important;
}
span.oh_speaker_text {
color: #ffff00 !important; /* yellow */
}
span.oh_speaker_1 {
display: block;
color: #00ffff; /* aqua */
}
span.oh_speaker_2 {
display: block;
color: #80ff00; /* bright green */
}
span.oh_speaker_3 {
display: block;
color: #ff0000; /* bright red */
}
span.oh_speaker_4 {
display: block;
color: #ff00ff; /* fuchsia */
}
span.oh_speaker_5 {
display: block;
color: #ffbf00; /* orange */
}
The Digital.Grinnell Oral History Workflow
InqScribe IOH Transcription Workflow
Grinnell College employs the transcription workflow described here when preparing oral histories for ingest into Digital Grinnell. This workflow includes a commercially available software tool called InqScribe and at Grinnell transcribers also frequently use a VEC USB Footpedal to help control playback of audio to be transcribed.
Training Video
An 11.5 minute long is available to reinforce the concepts presented below.
The video moves very quickly, compressing a 2-hour transcription session down into 11.5 minutes. You may find it necessary to slow the playback down, or rewind and repeat portions of the video, using the controls available in your browser.
Workflow Description
A typical transcription session generally involves the following steps…
OHScribe creates a new cue every time it encounters a timecode, so every timecode should be followed immediately by a newline, speaker name and pipe character. For areas of the recording that are dense with speaker changes, no timecode is needed to transition to the next speaker, i.e. the transcriber can represent a change in speaker by entering a newline, the speaker name and pipe character to start the next speaker’s dialogue. This will result in a cue that has mutliple speakers.
InqScribe Snippets and Triggers (Shortcuts)
InqScribe allows a transcriber to define and use Snippets, short bits of frequently-repeated text, with associated triggers or keyboard Shortcuts that make it easy to quickly add key elements to a transcript. The following are samples of Snippets and their corresponding Triggers/Shortcuts used in conjunction with our workflow.
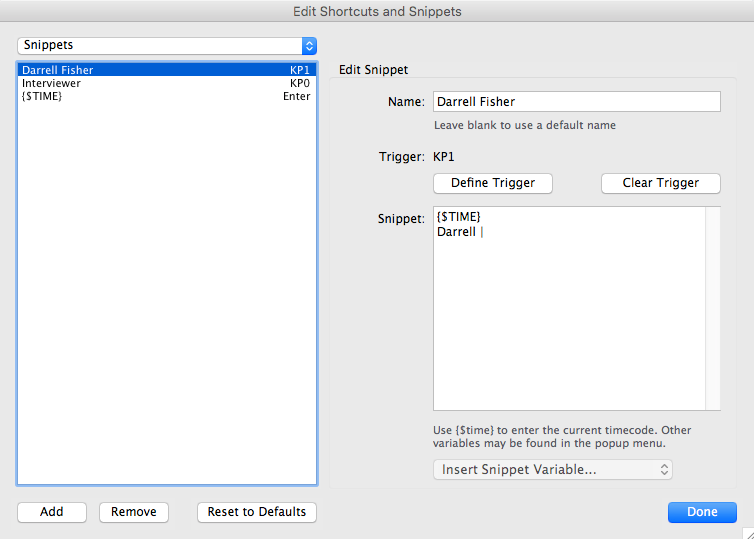
The above image is an example of a Snippet we refer to as a ‘Speaker Timecode’. When triggered, this snippet will insert:
- A timecode, the
${TIME}variable portion of the snippet, and - A name identifying the speaker providing the transcribed text that will follow.
In this example the speaker’s name is ‘Darrell’ and that name is followed by a REQUIRED space and a pipe character, the vertical bar, in the portion that reads Darrell | . There is a space after the pipe character so as to allow the thranscriber to simply press the triger and then immediately start to type the dialogue into InqScribe. OHScribe does not currently correctly parse a pipe character from other text unless it is surrounded by spaces on either side.
If a speaker has a double first name, the name will need to be hyphentated because OHScribe will only identify one word/name, separated from others by spaces, as the trigger name for the speaker. The first name in the <speaker> FirstName LastName </speaker> tag MUST match the name that follows after the timecode.
Note also that in this example our Speaker Timecode snippet is named Darrell Fisher and it is assigned to trigger KP1 which has a corresponding keyboard shortcut. The name of the timecode snippet is not important, and can be left vague/general, as with the Interviewer example.
Any additional speakers can be represented in the same way by selecting ‘Add’ and then filling in the correct information similarly to the example above.
Each time a new speaker is introduced, there must be <speaker> FirstName LastName </speaker> line added between the timecode and the FirstName | . Each speaker should only have one instance of speaker tags in the InqScribe file.
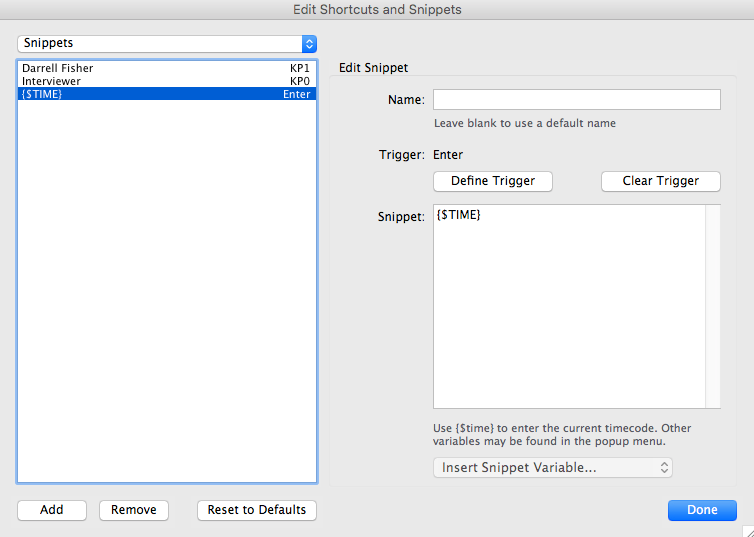
The second image, immediately above, is an example of a Snippet we refer to as a ‘Raw Timecode’. When triggered, this snippet will insert:
- A timecode, the value of the
${TIME}variable referenced in the snippet, and nothing else.
Note that a Raw Timecode has no associated speaker name as it’s intended to be used when the speaker name is unknown, or when there isn’t time during transcription to pause for identification of the next speaker.
This example Raw Timecode snippet is named {$TIME} and it is assigned to the Enter trigger which generally corresponds to the Enter or Return key on the keyboard.
Export to XML
Once the transcription and timecodes are in place, save the InqScribe file and export it to an XML file by selecting File -> Export -> XML.
And that’s a wrap. Until next time, stay safe and wash your hands! 😄